
A few weeks ago I received a surprisingly open and honest feedback on my recently published article "13 tips ...". I never ever expected that! After a short email exchange, I was allowed to publish the feedback anonymously. Below is the incredible feedback[3]. You see, you are not alone with the challenges of a Data Vault project:
Hi Dirk
Thanks for sending me the English version of the paper. I'm based in […] [1] and Data Vault is not generally established here yet.

Model driven decision making
During #XP19 you’ll be able to take part in our (Matze and myself) deep dive session about Model driven decision making: Data (Vault) Modeling and Deep Learning. It has been designed to give you a (very) short hands-on and practical guidance.
What is this 15 minute deep dive session about at #XP19?

FastChangeCo and the Fast Change in a Hybrid Cloud Data Warehouse with elasticity
What is this 20 minute talk about at #BAS19?
The fictitious company FastChangeCo has developed a possibility not only to manufacture Smart Devices, but also to extend the Smart Devices as wearables in the form of bio-sensors to clothing and living beings. With each of these devices, a large amount of (sensitive) data is generated, or more precisely: by recording, processing and evaluating personal and environmental data.

Oder wie Sie erfolgreich jede Ebene des Data Warehouse torpedieren
Sie sind erfolgsverwöhnt und haben das ewige Schulterklopfen satt? Sie wollen nicht auch noch bei Ihrem ersten Versuch zur Umsetzung eines Data-Vault-Projekts so erfolgreich sein, dass alle Kollegen neidisch werden?

This blog post will be a review of the Global Data Summit. But first I would like to lose a few sentences about the Advanced Data Vault & Ensemble Modelling meeting, organized by Hans Hultgren and Remco Broekmann. It is an event that brought together experienced data modelers from all over the world (New Zealand, South Africa, Europe and the USA) around Data Vault, Focal and Ensemble Logical Modeling (ELM). That sounds promising, doesn't it?
Advanced Data Vault & Ensemble Modelling
There were two interesting days with many topics around Data Vault and ELM, which were put up for discussion. The idea behind the meeting is to think further, e. g. where to go with Data Vault and ELM and what the participants can contribute from their own experiences. I personally find some of the points discussed very interesting and exciting and should be pursued further. With others I have to go into myself and continue researching. Most likely, I'll go into other blog posts on different topics, such as the discussion about concatenated key, partitioned links or how you can do without satellites on links. I will see.
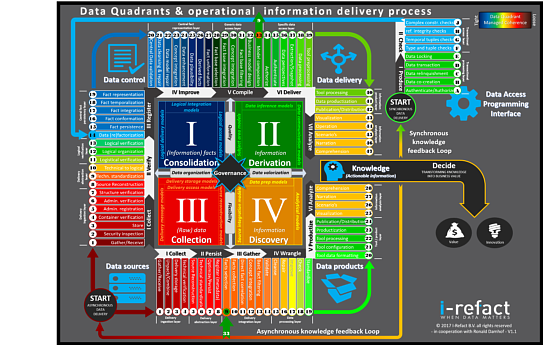
As already mentioned in my previous blogpost I will give a talk at the first day of the Data Modeling Zone 2017 about temporal data in the data warehouse.
Another interesting talk will take place on the third day of the DMZ 2017: Martijn Evers will give a full day session about Full Scale Data Architects.
Ahead of this session there will be a Kickoff Event sponsored by I-Refact, data42morrow and TEDAMOH: At 6 pm on Tuesday, 24. October, after the second day of the Data Modeling Zone 2017, all interested people can meet up and join the launch of the German chapter of Full Scale Data Architects.
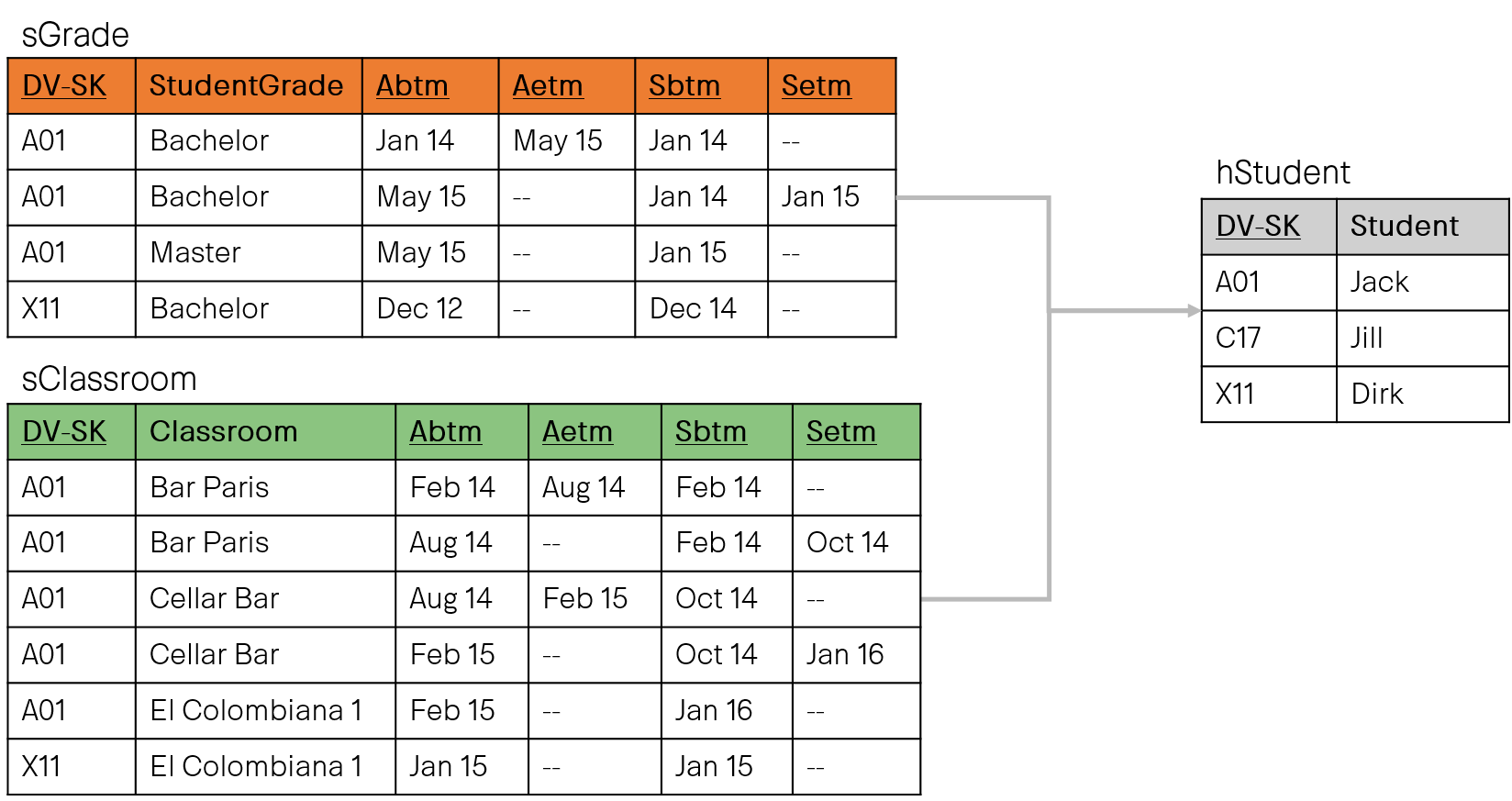
After all, I am very happy to be a speaker at this year's Data Modeling Zone in Düsseldorf. Again, like at the Global Data Summit, I'm talking about one of my favorite topics: Temporal data in the data warehouse, especially in connection with data vault and dimensional modeling.
Seite 6 von 13